We recently did an internal knowledge meeting about Distributed Revision Control at work. Rather than post my rugged presentation on SlideShare, I figured I'd rather pull together my notes into a blog-post.
In our presentation, we were supposed to go head-on-head with Git vs Mercurial (as these were our DSCM finalists). Most of my notes are pro-Git, although I'm equally fine with adopting Mercurial.
So, what's the deal with distributed?
Basically, instead of having a single repository on a central server, everyone has their own repository.
These repository are the same, because internally they have the same identifier-keys (SHAs) and history.
Since all bits and pieces are globally understood in relation to eachother, you can bring together changes from two separate repositories pretty easily.
Why would anyone want to distribute their repos?
You want to let people work without ruining the main line.
Consider feature branches.
Remember that feature branch we did that time? It was about three weeks of development, and then *bam* merge hell!
With DSCM, after developing a feature for weeks, you continuously pull in latest main development to your feature branch and fix any conflicts as soon as they arise. Then later when you want to apply your new feature back to the main line: Schmock, done. No conflicts.
We do suffer with branching and merging. Merging costs us thousands of € every month (we maintain a development branch and a stable branch). We're basically manually maintaining many versions in parallel. This is expensive.
If you are distributed, branching/merging has to be easy, cause everyone kind of has a branch in their local copy. Every "update" is actually a merge from one repo to another.
Performance
When you've cloned a repository, you have the whole history inside (compressed, this is just a fraction of the size of the working directory).
Doing a diff takes milliseconds (as opposed to over a minute for our main product in Subversion).
Open source vs companies
Many of the distributed advantages appear in a large network, where you have hierarchies of trust and delegation. People who know each other merge upwards. This works really well, linux kernel merges 22.000 files a day (I think Linus said that in his talk, see resources below).
If you get merge conflicts on top, you simply reject the patches coming in, tell them which repository they have to comply with, they do the work, and you can pull in without any conflicts.
If you're in a tightly controlled corporate environment, centralized can work well. But they have problems with distributed groups, which gets tacky with network access.
In a company you have that feeling that everyone should be committing into the main repository. Distributed SCMs, you fake this by having a repository act as central.
A history of version control (for those who are interested)

Nicknamed the fast version control system. Traditionally had very poor windows support, but this has been resolved.
Git has a big presence in communities like:
All objects have a SHA key, which is used to identify them across repositories. Powerful concept.
Does not work on deltas, like with SVN. Each time you commit, it stores a snapshot of what all the files in a tree look like. Changes are calculated by diffing the states in two commits.
A blob is defined by it's data. Two equal parts of data will share the same blob, referenced by two trees.
All these objects are stored inside the .git directory in a project. When you jump between branches, git shuffles the objects around.
Committing
When you commit, your commit the changes that are in the index, a kind of staging area. Not directly from working directory. git add adds resources to the index. git commit -a does both in one go.
Branching
branches are easy. Create branch with
git branch [branchname] ,and git checkout [branchname] to switch to it.. git branch -d to delete.
(will enforce that you merge back before deleting, unless you use -D)
Stashing is a nice way to dump current work so you can temporarily switch to another branch to do some hot fixes.. http://gitready.com/beginner/2009/03/13/smartly-save-stashes.html
Merging
git merge [branchname]. Pretty straight forward.
Conflicts get conlict-markers like those in subversion, but git won't let you commit until you have resolved all conflicts (you have to run git add on the resolved files).
If all goes to hell, run
git reset --hard HEAD
If you want the changes from another repository, you have to pull in the changes, git pull
You can also do this in two steps: git fetch (updates index with remote tracking branch stuff) and git merge.
Pushing
When you want to pretend having a central repo where users use git push to push in their changes. If you have a patch you want to serve back to the authors of an open source project, you give them a pointer to your repo and ask them to pull. They then pull, try it out locally, and then push to their repo.
Log
Git has some very powerful logging commands that you can use to search through the history of the repo, shaping the output to your need. Simply git log is usually ok for looking at the last couple of commits, but here's a fancier example:
git log --pretty=format:"%h by %an - %ar" --author=Ferris
Tagging
There are two kinds of tags: Light-weight ones, that are just an alias for a commit (SHA), and tag objects, than can have author, message, etc. This is useful for signing with GPG keys etc.
Rebasing
This is where Git really starts to shine. It lets you screw around with your commits as much as you want to fix them up, merge, edit, etc. before pushing up.
http://tomayko.com/writings/the-thing-about-git
It lets you work in your personal style. I used to say "work on one thing at the time, and use svn sync, keep it clean". Lots of people find this disturbs their flow. Git allows you to keep coding and VCS separate. If you wanna make a mess, you can clean it up later.
This relates to The tangled workspace problem described in the blogpost above. You want a SCM that manages revisions for you, not makes it a hassle.
Workflow, conventions
PRO: You can put any kind of workflow, so its possible to make it fit for us.
This article shows some *great* examples of branches and workflow: http://nvie.com/git-model
See also Git commit policies: http://osteele.com/archives/2008/05/commit-policies
Weaknesses of Git
Some ideas on http://hgbook.red-bean.com/read/how-did-we-get-here.html#id343368
although most of the pain points seem to be outdated.
"hg st" and "hg ci" rules over git status og git commit -a (fix with aliases)
$ cat ~/.gitconfig
[alias]
ci = commit -a
co = checkout
st = status -a
It's complex. Many top level commands that you have to navigate around.
Git has poor Eclipse support.
In other words, if we move to Git now, we have to get used to using the command line (yes, we're spoiled with Subversion support in Eclipse).
Mercurial has a great Eclipse plugin though.
Git is slow on windows (see the GStreamer mail discussion referenced below, or the benchmarks).
Pain points about Mercurial, or pro-Git
Linus says they have the same design, but Git does it better.
hgEclipse Synchronize view is useless to commit from! Have to refresh a lot. (performance is supposedly fixed in the recent version of the plugin around the end of May 2010).
The Mercurial documentation actually points out the differences in a pretty fair and honest way:
http://mercurial.selenic.com/wiki/GitConcepts
Git has longer time in the field than Mercurial.
Git is written in C, while hg is written in python. Which is faster? :P
Git "has more legs". It's easier to do something fancy with using a couple of different git-commands, than to start coding Python.
Some performance benchmarks here: https://git.wiki.kernel.org/index.php/GitBenchmarks
In Git, you can modify previous commits (ammend).. You can do this with hg too, but you need to understand queues, and enable a plugin..
Pain point about Mercurial: Everytime you want to do something fancy, you have to enable a plugin (not just you, but every developer will have to do this on their machine).
Resources
If you read this far, here's the bottom line: Git and Mercurial have been around for five years now, and are ready for the mainstream. Going distributed will shake up and change your whole way of dealing with iterations, releasing, testing and developing (for the better). Start understanding them now, and start using them for your internal code.
I might repeat the core message of this in a future blog post, but for now, please read Joel Spolsky's reasoning in his Mercurial how-to.
Disclaimer: These notes were lashed together creating an internal presentation. I cannot vouch for their correctness. Please double-check the facts before going into an argument armed with anything from this post. Sorry that I haven't done proper source-referral.
In our presentation, we were supposed to go head-on-head with Git vs Mercurial (as these were our DSCM finalists). Most of my notes are pro-Git, although I'm equally fine with adopting Mercurial.
So, what's the deal with distributed?
Basically, instead of having a single repository on a central server, everyone has their own repository.
These repository are the same, because internally they have the same identifier-keys (SHAs) and history.
Since all bits and pieces are globally understood in relation to eachother, you can bring together changes from two separate repositories pretty easily.
Why would anyone want to distribute their repos?
You want to let people work without ruining the main line.
Consider feature branches.
Remember that feature branch we did that time? It was about three weeks of development, and then *bam* merge hell!
With DSCM, after developing a feature for weeks, you continuously pull in latest main development to your feature branch and fix any conflicts as soon as they arise. Then later when you want to apply your new feature back to the main line: Schmock, done. No conflicts.
We do suffer with branching and merging. Merging costs us thousands of € every month (we maintain a development branch and a stable branch). We're basically manually maintaining many versions in parallel. This is expensive.
If you are distributed, branching/merging has to be easy, cause everyone kind of has a branch in their local copy. Every "update" is actually a merge from one repo to another.
Performance
When you've cloned a repository, you have the whole history inside (compressed, this is just a fraction of the size of the working directory).
Doing a diff takes milliseconds (as opposed to over a minute for our main product in Subversion).
Open source vs companies
Many of the distributed advantages appear in a large network, where you have hierarchies of trust and delegation. People who know each other merge upwards. This works really well, linux kernel merges 22.000 files a day (I think Linus said that in his talk, see resources below).
If you get merge conflicts on top, you simply reject the patches coming in, tell them which repository they have to comply with, they do the work, and you can pull in without any conflicts.
If you're in a tightly controlled corporate environment, centralized can work well. But they have problems with distributed groups, which gets tacky with network access.
In a company you have that feeling that everyone should be committing into the main repository. Distributed SCMs, you fake this by having a repository act as central.
A history of version control (for those who are interested)
- CVS
- Dates back to 1986 (Holland, shell scripts, replacing RCS from 1982)
- Subversion (started in 2000)
- Was supposed to solve the problems CVS had
- No renaming and non-atomic commits
- But did it really? Still centralized, rename is copy+delete
- No merge tracking, or history-aware-merging
- Merging is PITA, renames and moves not supported
- Dominated the open source/company world from ~2005
- There was VSS (ms), ClearCase (ibm), but these sucked. Perforce (@Google).
- Gnu-Arch (the original)
- Started in 2001, Tom Lord (thereby tla)
- Semi-distributed (you could cherry-pick commits from other repos, but still one centralized)
- But: Slow, hard-to-use, funky conventions
- Declared dead/deprecated 2009
- Darcs (Built in Haskell to defeat SVN and CVS)
- Started as an addition of "theory-of-patches" to Gnu-Arch
- Around 2002, David Roundy
- My feeling: Popular and good, besides, Haskell is cool and fast
- Unfortunately, some algebra bugs in there, recursive merging
- They've had a few major bugs for a long while, but being resolved..
- Bazaar (built by Canonical for open source hackers)
- Predecessor, baz, based on Gnu Arch
- Current python-powered started as prototype in 2004
- Used by Ubuntu, MySQL, Emacs
- It's easy and good, but a bit slow and inefficient
- BitKeeper (proprietary, took the best ideas from DSCM, 1997)
- Comes from Sun/TeamWare, which comes from SCCS (xerox original)
- "Doubles software development productivity"
- Sold to big businesses
- Controversially: Was free for, and used by Linux since 2002
- (Before this they used tarballs and patches)
- In 2005, they wanted out of the Linux Kernel (fear of competitors developing)
- Linus started Git
- Matt Mackall announced Mercurial just a few days after
- Others: SVK, D-CVS, Monotone (Linus dropped monotone cause the author was on holiday)

Above: Timeline illustration of roughly when the revision systems were created. Distributed systems above the orange bar, centralized below.
About GitNicknamed the fast version control system. Traditionally had very poor windows support, but this has been resolved.
Git has a big presence in communities like:
- Linux
- Perl
- Gnome
- Qt
- Ruby on Rails
- Google Android
- http://github.com/repositories
- http://gitorious.org/
- Blob: Chunk of binary data, generally files
- Tree: Directories
- Commit: A tree at a certain point in time
- Tag: Pointer to a commit
All objects have a SHA key, which is used to identify them across repositories. Powerful concept.
Does not work on deltas, like with SVN. Each time you commit, it stores a snapshot of what all the files in a tree look like. Changes are calculated by diffing the states in two commits.
A blob is defined by it's data. Two equal parts of data will share the same blob, referenced by two trees.
All these objects are stored inside the .git directory in a project. When you jump between branches, git shuffles the objects around.
Committing
When you commit, your commit the changes that are in the index, a kind of staging area. Not directly from working directory. git add adds resources to the index. git commit -a does both in one go.
Branching
branches are easy. Create branch with
git branch [branchname] ,and git checkout [branchname] to switch to it.. git branch -d to delete.
(will enforce that you merge back before deleting, unless you use -D)
Stashing is a nice way to dump current work so you can temporarily switch to another branch to do some hot fixes.. http://gitready.com/beginner/2009/03/13/smartly-save-stashes.html
Merging
git merge [branchname]. Pretty straight forward.
Conflicts get conlict-markers like those in subversion, but git won't let you commit until you have resolved all conflicts (you have to run git add on the resolved files).
If all goes to hell, run
git reset --hard HEAD
If you want the changes from another repository, you have to pull in the changes, git pull
You can also do this in two steps: git fetch (updates index with remote tracking branch stuff) and git merge.
Pushing
When you want to pretend having a central repo where users use git push to push in their changes. If you have a patch you want to serve back to the authors of an open source project, you give them a pointer to your repo and ask them to pull. They then pull, try it out locally, and then push to their repo.
Log
Git has some very powerful logging commands that you can use to search through the history of the repo, shaping the output to your need. Simply git log is usually ok for looking at the last couple of commits, but here's a fancier example:
git log --pretty=format:"%h by %an - %ar" --author=Ferris
Tagging
There are two kinds of tags: Light-weight ones, that are just an alias for a commit (SHA), and tag objects, than can have author, message, etc. This is useful for signing with GPG keys etc.
Rebasing
This is where Git really starts to shine. It lets you screw around with your commits as much as you want to fix them up, merge, edit, etc. before pushing up.
http://tomayko.com/writings/the-thing-about-git
It lets you work in your personal style. I used to say "work on one thing at the time, and use svn sync, keep it clean". Lots of people find this disturbs their flow. Git allows you to keep coding and VCS separate. If you wanna make a mess, you can clean it up later.
This relates to The tangled workspace problem described in the blogpost above. You want a SCM that manages revisions for you, not makes it a hassle.
Workflow, conventions
PRO: You can put any kind of workflow, so its possible to make it fit for us.
This article shows some *great* examples of branches and workflow: http://nvie.com/git-model
See also Git commit policies: http://osteele.com/archives/2008/05/commit-policies
Weaknesses of Git
Some ideas on http://hgbook.red-bean.com/read/how-did-we-get-here.html#id343368
although most of the pain points seem to be outdated.
"hg st" and "hg ci" rules over git status og git commit -a (fix with aliases)
$ cat ~/.gitconfig
[alias]
ci = commit -a
co = checkout
st = status -a
It's complex. Many top level commands that you have to navigate around.
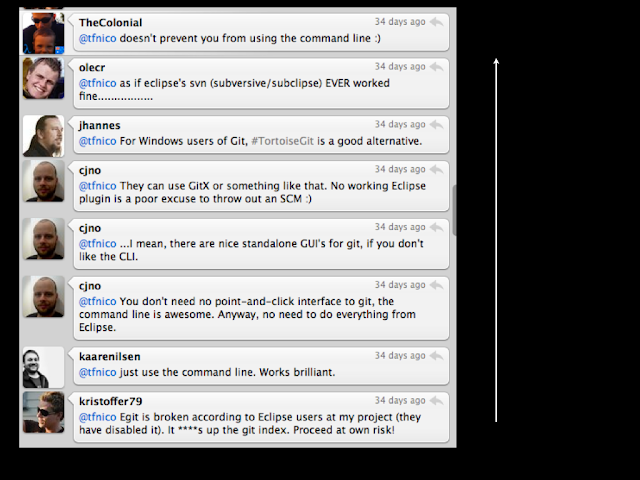
Git has poor Eclipse support.

Above: My twitter buddies give their input on how the Eclipse Git plugin is working.
In other words, if we move to Git now, we have to get used to using the command line (yes, we're spoiled with Subversion support in Eclipse).
Mercurial has a great Eclipse plugin though.
Git is slow on windows (see the GStreamer mail discussion referenced below, or the benchmarks).
Pain points about Mercurial, or pro-Git
Linus says they have the same design, but Git does it better.
hgEclipse Synchronize view is useless to commit from! Have to refresh a lot. (performance is supposedly fixed in the recent version of the plugin around the end of May 2010).
The Mercurial documentation actually points out the differences in a pretty fair and honest way:
http://mercurial.selenic.com/wiki/GitConcepts
Git has longer time in the field than Mercurial.
Git is written in C, while hg is written in python. Which is faster? :P
Git "has more legs". It's easier to do something fancy with using a couple of different git-commands, than to start coding Python.
Some performance benchmarks here: https://git.wiki.kernel.org/index.php/GitBenchmarks
In Git, you can modify previous commits (ammend).. You can do this with hg too, but you need to understand queues, and enable a plugin..
Pain point about Mercurial: Everytime you want to do something fancy, you have to enable a plugin (not just you, but every developer will have to do this on their machine).
Resources
- Good book: http://progit.org/book/
- Good book: http://book.git-scm.com/
- Nice cheat sheet: https://git.wiki.kernel.org/index.php/GitCheatSheet
- Starter kit: http://gitready.com/
- A good Git talk by Schwartz for Google: http://www.youtube.com/watch?v=8dhZ9BXQgc4
- Linus' more fluffy Git talk for Google: http://www.youtube.com/watch?v=4XpnKHJAok8
- Intro for CS students: http://www-cs-students.stanford.edu/~blynn/gitmagic/
- Potential Git management tool: http://code.google.com/p/gerrit/ used by Android
- Distributed vs centralized repo: http://www.infoq.com/articles/dvcs-guide
- Frequently used Git commands: http://wiki.sourcemage.org/Git_Guide
Comparing Git and Mercurial:
- Nice: http://gitvsmercurial.com/
- http://www.wikivs.com/wiki/Git_vs_Mercurial
- http://versioncontrolblog.com/comparison/Git/Mercurial/Subversion/index.html
- http://whygitisbetterthanx.com/#hg
- GStreamer's discussion on switching to Git: http://gstreamer-devel.966125.n4.nabble.com/GStreamer-switching-to-git-td966534.html
- Another "Why we chose git": http://unethicalblogger.com/node/198
If you read this far, here's the bottom line: Git and Mercurial have been around for five years now, and are ready for the mainstream. Going distributed will shake up and change your whole way of dealing with iterations, releasing, testing and developing (for the better). Start understanding them now, and start using them for your internal code.
I might repeat the core message of this in a future blog post, but for now, please read Joel Spolsky's reasoning in his Mercurial how-to.
Disclaimer: These notes were lashed together creating an internal presentation. I cannot vouch for their correctness. Please double-check the facts before going into an argument armed with anything from this post. Sorry that I haven't done proper source-referral.
[disclosure, I'm a Mercurial dev ;)]
ReplyDeleteWhen you write:
Git has longer time in the field than Mercurial.
Git is written in C, while hg is written in python. Which is faster? :P
I'm not sure what you mean, they both were started about the same day.
And Mercurial is actually written in C+Python, all the CPU intensive stuff is in C modules (that's where python shines, you get speed of development, and rewrite later the critical parts). I think the only price that is paid is the startup time of the interpreter.
(And a good SCM should be IO-bound, Mercurial usually is)
Cheers (and have fun with the DVCS that suits you most ;)
Thanks for your comment!
ReplyDeleteWhen I wrote the "longer time in the field" note, it was before I realized that both projects were started at the same time. Sorry bout that.
I could argue that the man-hours put into developing and using Git are greater than for Mercurial, based on my gut feeling (more, bigger projects, github,,,), but anyhow, this is not a good factor for choosing between Git and Mercurial. Nor is performance, IMHO.
I'm currently having fun with Git, trying to figure out productive use of git/svn. Our presentation internally didn't seem to convince much of the team, I'm afraid, so my strategy now is to get some transition going, and then propose a switch some day in the future when most of the team have grown to like Git/Mercurial.
Perhaps I should focus more on Mercurial to ease transition, but currently, the functionality in git-svn seems to surpass the ones of hg --svn. We're still probably gonna land on using Mercurial for our main product in the end, due to better Windows/IDE-support.
For the subversion interop, it really depends on the tools. Although I didn't heavily use it, hgsubversion is quite advanced (and in some cases might be ahead of git-svn due to the proximity of the author (working @google) with former svn devs).
ReplyDelete(hg convert is more basic and only for one-way conversion, and I haven't always heard good things of hgsvn).
I think mercurial support on windows is pretty good, at least two of the core devs were first involved in the project because they were paid by their compagny to improve the windows support ;)
From what I've heard tortoisehg provides a very nice experience on windows, or in general for GUI oriented people (I sometimes uses it on linux, it's a good repo browser etc.).
Thanks for the pointers. I'll investigate hgsubversion further :)
ReplyDeleteI really like this article and think it does a good job of bringing up some of the main points about git and mercurial. I have been using git for over a year now and have enjoyed it for the most part other then support on windows (which is a lot better now then it used to be).
ReplyDeleteI started using mercurial with another group and I have to say that I really enjoy a lot of what it does and how things work with it. It is much simpler to get running and working well on windows IMO but at the end of the day it really isn't a big deal to use one over the other.
I personally think that its good to learn to use both as there are going to be times if you work in the open source community that you will grab code from either location, and to get a lot of the basics down is really a snap once you understand the concept of a DSCM.
My thoughts too, Mike. I think it'll do good to know both tools well. Also a good thing is that they're competing on features, so I think they drive each other into improving a lot, cause people from one camp will always be saying "but Git can do X", or "Mercurial is faster at Y", etc.
ReplyDelete> Our presentation internally didn't seem
ReplyDelete> to convince much of the team, I'm afraid
http://nvie.com/posts/a-successful-git-branching-model/
May be, this article would be a good food for thought for the people. Because it describes rather an intresting and advantageous development model within a team. Though it's a story about Git, it may also be easily projected to Hg, I suppose.
Hi Andrei, thanks for commenting!
ReplyDeleteI'm familiar with the git-flow model. I admit I haven't communicated it to the team, cause I feel "we're not quite there yet".
As an update, we are still on Subversion, although we've started using Mercurial for a number of projects outside our core product. We're also maintaining a Git-mirror of our SVN repo, so people who wish to use Git in their daily work are free to do so. So, half a year later, it's slowly catching on :)
I'm hoping that when the time comes where we make the full switch, and leave SVN behind, that we can make use of git-flow, or a similar model.