It is challenging to make a clear distinction that separates WCM systems from similar information systems. To explore this one must understand the possible ways to do web content management. Various architectures of implementation exist. One possible categorization is presented here.
These four levels are a way to divide the physical management of content. In general one can say that the higher use of web content in a company, the higher level its WCMS implementation should be. The separation is historical and drawn from my personal experience with web development through the last decade, therefore the evolutionary approach.
Static files on a web-server

The most basic strategy is to compose static HTML files and transfer these to a web server capable of serving such files to clients connecting to the web-site. It is possible to apply styles to the pages, for example with the help of cascading style-sheets (CSS).
Content wrapped in templates

The next level of content management is attained when the editor wishes to re-use the design of the web-site by dynamically including content into a frame of finished design, or a template. The content is typically contained in a text file the dynamic page engine
can read. Examples of technology capable of this are Server-Side Includes (SSI), Simple Common Gateway Interfaces (CGI) [Dudek, 2003] and XML-documents using XLST transformations [Weitzman, 2002]. The HTML standard also has a command called frames to include nested web-pages, although professional web designers and developers frown upon the use of this deprecated function [Nielsen, 1996].
Dynamically generated content

More complexity arrives as the re-use of templates is pushed further, having a template dynamically selecting content source based on a dynamic parameter. This is not possible with SSI as you have to provide each separate content page with its own physical HTML file. This means two files for any page on the web-site, one with content, another with design. Many find this to be too cumbersome and end up putting both files inside one, thereby mixing content and design. If a dynamic parameter is possible, as is the case with scripting languages such as PHP (a recursive acronym), Active Server Pages (ASP) or JavaServer Pages (JSP), one can have the template select and read the content file conditionally, thereby removing the need for its own HTML file [Challenger, 2005].
Content stored in a repository
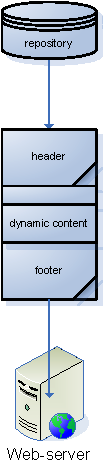
The next step is to remove the content files to replace them with something more scalable. Native files have many disadvantages: they are not versionable, backup-routines require mirrored copies, search is not easy, binary files like picture and video can not be wrapped with meta data, there is no fitting access control and the possibilities for collaboration is limited. Instead the content is put inside some kind of repository, most likely a database, illustrated in Figure 5. Management of the content is subsequently handled by middle-ware that replace the programming interface of the file system.
A system developer will recognize this three-level architecture of the Model-View-Control (MVC) pattern [Reenskaug, 1978]. The model consists of the content in the database, the view-layer is provided by templates, and control is implemented in the middle-ware. The MVC is a pattern that offers a separation of concerns in the WCMS.
The next level
It is possible to invent further levels of content management, but any present form of WCMS will most likely apply some variation of the last level. Future levels might include technologies focusing on content integration and service orientation with the use of web services and mash-up principles [First Author, 2006]. Another direction in improving performance is distributed CMS networks [Voras, 2005], [Canfora, 2002].
Canfora, G., Manzo, S., Rollo, V. F., Villani, M. L. 2002, "ContentP2P: a peer-to-peer content management system", conference proceedings from COMPSAC'02, IEEE
Challenger, J., Dantzig, P., Iyengar, A. 2005, "A Fragment-Based Approach for Efficiently Creating Dynamic Web Content", 2, p. 359-389
Dudek, D. T., Wieczorek, H. A. 2003, "A Simple Web Content Management Tool as the Solution to a Web Site Redesign", conference proceedings from SIGUCCS'03, ACM
First Author 2006, "The Monster Mash-Up" [http://www.firstauthor.org/research_tools.html#Mashups] Retrieved 22. April, 2006
Nielsen, J. 1996, "Why Frames Suck (Most of the Time)" [http://www.useit.com/alertbox/9612.html] Retrieved 22. April, 2006
Reenskaug, T. M. H. 2006, "MVC XEROX PARC 1978-79" [http://heim.ifi.uio.no/~trygver/themes/mvc/mvc-index.html] Retrieved March 26, 2006
Weitzmann, L., Dean, S. E., Meliksetian, D., Gupta, K., Nianjun, Z., Wu, J. 2002, "Transforming the Content Management Process at ibm.com", Experience Design Case Study Archive
Voras, I., Zimmer, K., Zagar, M. 2005, "Distributing Web-based Content Management System - "FERweb"", conference proceedings from ITI 2005,
Comments
Post a Comment